Bayesian Blocks Examples
| Main Page |
| Distribution and References |
| Functions |
| Examples |
| Downloads |
 |
| MIT: Captioning & Accessibility |
Bayesian Blocks for Gratings Data - EXPERIMENTAL!
This is still in the experimental stages, but preliminary tests have been promising enough to encourage people to try this on their own data. Note that what follows are my own thoughts about extending the Bayesian Blocks algorithm to gratings data, but don't necessarily reflect the views of Jeffrey Scargle, the originator of the algorithm. (We're both still scratching our heads about how best to tackle the problems described below.) For those that look at the algorithm and try it out on gratings data, I would very much appreciate feedback, positive or negative.There is nothing particular about the Bayesian Blocks algorithm that says that one is looking for blocks within a time-ordered series. Instead, the algorithm can be applied equally well to searches for blocks within wavelength-ordered series. The catch here is that whereas it is not unreasonable to expect that count rate variations with time are solely (or, at least, almost exclusively) due to variations intrinsic to the source, count rate variations as a function of wavelength (e.g., a gratings spectrum) will be due to both the intrinsic spectrum of the source, and the response of the detector. Furthermore, one typically can successfully fit a spectral model that at least describes the broad band features of the source reasonably well. What one would like instead is an algorithm that searches for significant residuals (emission and absorption lines, as well as edges) in the data, after a broad band model has been applied. Bayesian Blocks, with essentially no modification, seems to be successful in this regard.
Here's a little math, outlining my thoughts behind the application of the algorithm to gratings data. I'm mostly following, but modifying slightly, the definitions found in the forthcoming paper by Jeffrey Scargle. An important point to note is that as for the usual applications of the algorithm, we wish to consider Poisson statistics for the number of counts per (wavelength) bin, which we will label with subscript n. As for the usual application of the algorithm, we define a `likelihood function' for the bin as

 are the detected counts in the bin, and
are the detected counts in the bin, and
 is the total count rate, folding in detector
efficiencies, dead time corrections, etc. This count
rate can be defined to be
is the total count rate, folding in detector
efficiencies, dead time corrections, etc. This count
rate can be defined to be

 is the model of the ``true'' Poisson rate,
is the model of the ``true'' Poisson rate,
 is
the efficiency multiplied by the bin width, and
is
the efficiency multiplied by the bin width, and  is
going to be the variable that we marginalize the likelihood over.
is
going to be the variable that we marginalize the likelihood over.
 is our model count rate (folding in
efficiencies,
bin width, etc.) for
each bin.
is our model count rate (folding in
efficiencies,
bin width, etc.) for
each bin.
We can then form a global likelihood for a `Bayesian Block' indexed by k, which consists of bins ranging from 1 to M. This global likelihood is given by


Here's the somewhat controversial part: Let's choose 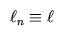 , i.e., uniform for all bins, and marginalize the
likelihood using the prior:
, i.e., uniform for all bins, and marginalize the
likelihood using the prior:


 is the total counts in the block. This is almost
exactly the same as found in the original derivation of `Bayesian
Blocks', except for the
is the total counts in the block. This is almost
exactly the same as found in the original derivation of `Bayesian
Blocks', except for the 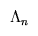 found in the
denominator, which represents the broad band model count rate in
units of counts per bin. (That is, the number of counts over the
total observation that you would expect to find in a given wavelength
bin, folding in all detector efficiencies, etc. This can, and usually
will be, a fractional number.)
found in the
denominator, which represents the broad band model count rate in
units of counts per bin. (That is, the number of counts over the
total observation that you would expect to find in a given wavelength
bin, folding in all detector efficiencies, etc. This can, and usually
will be, a fractional number.)
Enough Talk! Show Me Examples!
The above suggests a fairly straightforward application of the algorithm to residuals from spectral data. It requires only two quantities: detected counts per bin and model counts per bin. The former is given by the observation, and the latter is found in any broad band spectral fit. The above marginalized likelihood function is already calculated by the current version of the Bayesian Blocks code (within SITAR version 0.3.0), provided that one places the data counts in the definition ofcell.pops, and the model counts in
the definition of cell.size.
With SITAR version 0.3.0, the procedure below will implement a global optimization of the above marginalized likelihood function. (Note: This problem has made me rethink, somewhat, how one goes about applying Bayesian Blocks in `binned mode'. Later versions of SITAR might therefore require a different procedure. I will try to make everything backwards compatible, but no guarantees! Come back and look at these pages if you download any newer versions of SITAR. Note also that the following `redefinition' of `cell.size' is specific to the residual problem outlined above.)
The following example is ISIS specific; however, it would be very similar in Sherpa. In ISIS, execute the following series of commands.
% Load data & fit broad band model (not shown), and then store
% the results in structures. Note we store counts per bin, and
% not flux. We also presume evenly spaced wavelength bins
data_counts = get_data_counts();
model_counts = get_model_counts();
variable cell = struct{pops,size,lo_t,hi_t,dtcor};
cell.pops = data_counts.value;
cell.size = model_counts.value;
cell.lo_t = data_counts.bin_lo;
cell.hi_t = data_counts.bin_hi;
cell.dtcor = @cell.pops;
% A `frequentist interpretation' of the `significance level'
% for the parameter, alpha, is:
%
% Significance ~ 1. - exp(-alpha)
%
% This is only a *very* rough proxy, and Monte Carlo or
% MARX simulations are probably necessary to quantify this.
% It's on the agenda for further research.
variable alpha = 4.5;
variable ans = sitar_global_optimum(cell,alpha,3);
ans is a structure that now contains the locations of
`significant' change points in the residuals of the fit! It also
contains the (net) residual counts within the blocks. The following
set of code was used for visualization of the results (data-model
vs. wavelength, with block regions and normalized amplitude overlaid)
within ISIS:
label(
"Angstroms", "Residual",
"alpha="+string(alpha)+", "+string(100*(1.-exp(-alpha)))+"%"
);
% Regrid the data and model counts to the block grid.
variable data_rebin = rebin( ans.lo_t, ans.hi_t,
cell.lo_t, cell.hi_t, cell.pops );
variable modl_rebin = rebin( ans.lo_t, ans.hi_t,
cell.lo_t, cell.hi_t, cell.size );
id = open_plot("residuals.ps/vcps");
resize(20,0.9);
% Plot Data (cell.pops) - Model (cell.size)
set_line_width(1);
hplot( cell.lo_t, cell.hi_t, cell.pops-cell.size );
% The following presumes the original was 0.02 Angstrom bins.
% This is an average count per 0.02 Angstrom bin.
set_line_width(4);
ohplot( ans.lo_t, ans.hi_t,
(data_rebin-modl_rebin)*(0.02/(ans.hi_t-ans.lo_t)) );
close_plot(id);
Some Results
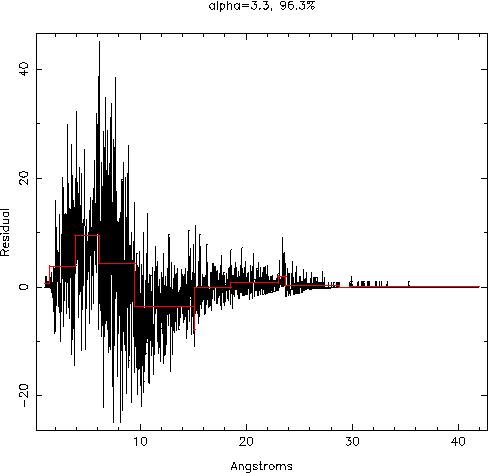
Here is a Chandra-HETG observation of a Gamma Ray Burst, possibly showing a line near 9 Angstroms. Methods that involved a successive series of rebinnings of the spectrum, to improve signal to noise, had previously revealed this feature with ~99% confidence (after the number of trials had been folded in). The Bayesian Block algorithm reveals the same feature, but with a lower (and again, only an approximate) significance level. The advantage of the Bayesian Blocks method is that no rebinning is required. The optimal binning is determined by the algorithm.
Here is a Chandra-HETG observation of an Active Galactic Nuclei. At
very low significance, only two lines are revealed. The more
significant of the two lines is the Fe line at the redshifted value of
1.9 Angstroms. That line remains in the residuals to greater than 95%
confidence levels.
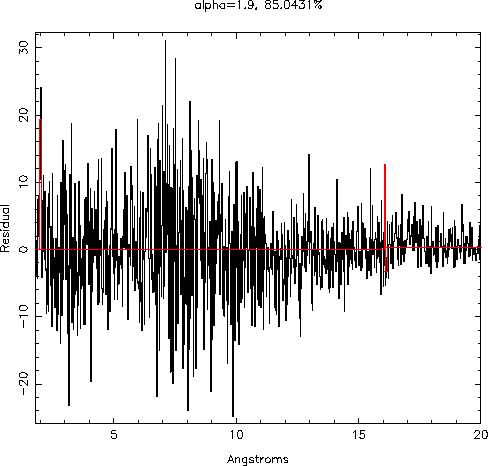
An important point to note about the above two results is that, in terms of residual counts, the detected lines seem to have residuals counts only comparable to many of the remaining residuals. However, since we have given the algorithm information about expected residuals counts (via the input of the model counts), it recognizes that the detected lines are in regions of low expected counts (due to low detector effective area and/or a weak spectrum in those regions).
Here is a final example, showing another Chandra-HETG spectrum of an
Active Galactic Nuclei. For this particular case, the algorithm is
picking up on the fact that we could have done a better job on the
broad band spectral fit. Hence the wide blocks with large residual
counts. The only significant line, or more likely, line complex,
resides in the 23-24 Angstrom region.